Hi, I’m Richard, AKA parsingphase
Are you here because I gave you a card while birding?
You might be looking for my main collection at
my Flickr account or
my iNaturalist sightings.
I take photos as a hobby, and write code as a profession.
On the software side, I build things in Javascript, Python, PHP and occasionally Java
I create documentation and guides as well as code
Commercially, I’ve worked for companies including -
- - Forcepoint
- - The London Internet Exchange
- - Snatch
- - Quidco
- - Amazon (at The Book Depository)
- - Fitch Learning
- - Dennis Publishing
- - The Mind Gym
I spent most of 2019 working on IX-API, and I’ve written up my experience
My online, personal projects include:
Rosetta PPJ (now with Java added!)

PHP | Python | Javascript | Java
A cheat sheet for anyone who, like me, finds swapping between multiple C-type languages confusing
Batbox
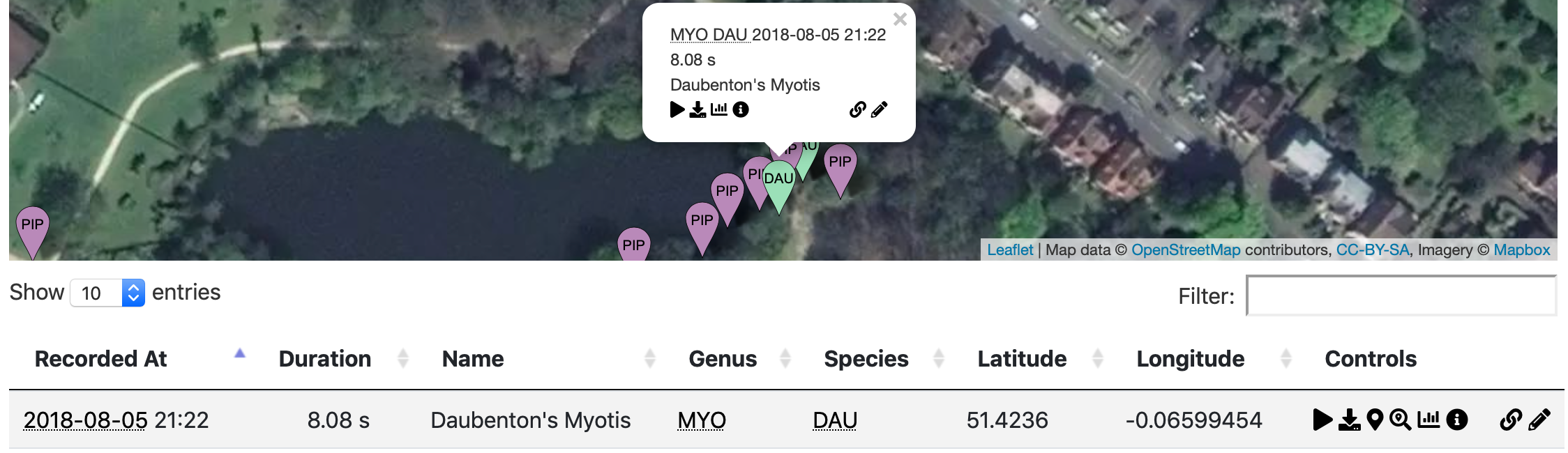
Python | Django | Javascript | jQuery | Docker
A geovisualisation and search tool for audio recordings of bats tagged with the GUANO format.
TDD Deciphered
PHP | TDD
A guide to Test-Driven Development built around a simulation of the Engima machine, based on my time volunteering at Bletchley Park
Beerbot

Python | AWS Serverless
A processing tool for paid supporters of Untappd, supporting stocklist management and consumption tracking
WeightInWhales

A small salute to the most important of standardised comparison units, the metric blue whale
PHP | Javascript | Symfony | Angular
TakeATicket

A management app for a karaoke-style event that I used to run with my wife and friends
PHP | Javascript | Symfony | jQuery | Docker
Minor projects
- https://github.com/parsingphase/technical-hitch
- https://github.com/parsingphase/4sl2gpx
- https://github.com/parsingphase/phetch
Created for clients and open-sourced
Social
- Twitter: @parsingphase
- Mastodon: @parsingphase@m.phase.org
Contact: richard@parsingphase.dev
Keys: https://keybase.io/parsingphase
Github: https://github.com/parsingphase
CV / Résumé: https://www.linkedin.com/in/richardgeorge